Nutanix Filesバージョン3.8から追加された新機能である、Smart DRについて紹介します。
Nutanix Filesの保護について
Smart DRの前にNutanix Filesの保護(バックアップなど含む)について、おさらいしてみます。
Nutanix FilesはNutanixの堅牢な分散アーキテクチャー上動作するため、仮想基盤のトラブルに引っ張られる形でFilesに影響が及びにくく、Filesに関しても高可用性を持ったアーキテクチャーで動作しており、物理的・論理的な要因によってデータロストしてしまうことは非常に稀だと考えています。
ただし100%安全なシステムは存在しないので、いざというときの備えは必要になります。
その備えとしてProtection DomainのAsync DRにてスナップショットを取得することで、Files全体の復元またはファイル/フォルダ単位の復元が必要なシチュエーションではSSR(Self Service Restore)を利用できるため非常に使い勝手がよいです。
このスナップショットをレプリケーションすることで、バックアップ用途としても非常に多く利用されています。
自然災害等で拠点そのものが利用できない状態で稼働をしたい場合には、DR側サイトでFilesを復旧して稼働させることが必要になります。
そのような場合もAsync DRのレプリケーション機能を利用すればDRサイト側で稼働させることはできます。
ただし、Async DRではスナップショットをもとにNutanix Filesのクローンを1から展開する仕組みのため、数十分ほどの時間を要していました。
過去の記事でNutanix Filesの保護について紹介しているので、詳しくはそちらをご覧ください。
Smart DR(Disaster Recovery)とは
今回紹介するNutanix Filesバージョン3.8から追加された機能であるSmart DRはFilesのDR環境構築において、さらなるメリットを提供することができます。
Smart DRを利用することにより、FilesをDR側サイトで復旧を行う際、より短いRTO(復旧目標時間)で利用を可能にし、フォルダ単位の細かな保護を実現できます。
Smart DRはメイン側に存在する任意の共有フォルダを指定して、一定時間ごと(最短10分)にDR側のNutanix Filesへレプリケーションを行います。
DR側のFilesはAsyncDRと異なり常時稼働(ただし、DR側は書込不可)している状態のため、クローンによる再展開が不要になり、数クリックの操作と僅かな時間(1~2分)でDR側サイトでFilesを利用可能にします。
なお、この機能を利用するにはPrism Centralが必要になり、Nutanix Filesが展開されているメイン側、DR側双方のクラスターをPrism Centralで管理している状態にする必要があります。
Prism Centralについては以下の記事をご覧ください。
Smart DRの設定方法
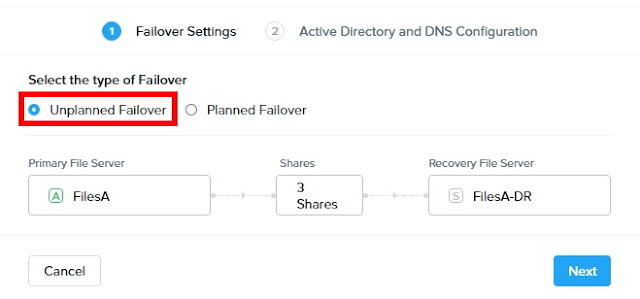
では、実際にSmart DR設定を行ってみます。
※今回は用意できる環境の都合上、同じクラスター内のFiles同士でSmart DRを設定してみます。
Smart DRはすべてPrism Centralから設定・操作を行います。
予めNutanix Filesを双方のクラスターで展開し、展開されているクラスターをPrism Centralから管理できる状態にしてください。
なお、Smart DRの設定と各操作の実行は以下の流れで行います。
はじめは左上の保護ポリシーを作成する作業から行い、それぞれのフローに従って設定やフェイルオーバーを行っていきます。
まずはPrism Centralに接続し、左側のメニューから[Services - Files]を選択します。
左側のメニューから[Data Protection - Policies]を選択し、「+New Policy」をクリックします。
まずは左側の項目にてSmart DRで保護対象のFilesを選択し、「Edit」をクリックします。
Files内の共有フォルダ一覧が表示されるので、保護対象の共有フォルダにチェックを入れます。
合わせて下部のチェックボックスにチェックを入れることで、今後Filesで作成された共有フォルダを自動的に保護対象に含めることが可能になります。
保護対象を選択後、「Done」をクリックします。
もとの画面に戻り、中央からレプリケーション間隔と右にはDR側クラスターに存在するレプリケーション先のFilesを指定します。
なお、レプリケーション間隔(RPO)は最短10分から指定が可能です。
また、初回のレプリケーションを即時またはスケジュールを指定して実行することが可能です。
今回作成したポリシーは、メイン側クラスターに存在する「FilesA」のという名前のFiles内に存在する全ての共有フォルダを、DR側クラスターの「FilesA-DR」というFilesへ10分毎にレプリケーションするように設定されたポリシーになります。
最後に任意のポリシー名を指定して、ポリシーの作成を完了します。
ポリシー作成後
ポリシーが正常に作成されると、一覧に作成したポリシーが表示されます。
左側メニューの[Protected File Servers]を選択すると、作成したポリシーに対応するFilesのステータスが表示されます。
アイコンの状態からメイン側クラスターに存在する[FilesA]がActiveとなり、DR側クラスターに存在する[FilesA-DR]がStandbyのステータスであることが確認できます。
左側メニューの[Replication jobs]からポリシーで設定された共有フォルダごとのレプリケーションのタスクが確認できます。
ポリシーにて設定したRPOを満たせていない場合は、[RPO Compliance]列が赤文字の✕が表示されます。
それぞれのタスクをクリックすると、詳細が確認できます。
共有フォルダの状態
レプリケーションが完了すると、双方のFilesで同じフォルダが存在しDR側には書込不可を表すアイコンが表示されます。
クライアントからも同様にフォルダとファイルが存在することが確認できます。
スタンバイ状態であるDR側のFilesに書込を実施しようとすると、不整合な状態にならないように拒否されるようになっています。
Filesのルート共有フォルダのNTFSアクセスを確認すると、スタンバイ状態のFilesには書込ができないように調整されていることがわかります。
概要・設定編のまとめ
今回はSmart DRの設定周りをメインに紹介させていただきました。
色々と説明しましたが、全体を通して見てみるとSmart DRの設定方法はPrism Centralから保護ポリシーを作成するだけのため、とても簡単に設定することができます。
次回はSmart DRによるフェイルオーバー時の動きなどを紹介させていただきます。
詳しくは次回の記事をご覧いただければと思いますが、フェイルオーバーなどの実施についても非常に簡単に実施することができます。